The DeepSeek Jolt: The Technological, Economic, and Geopolitical Impact
China's AI Open Source model - DeepSeek R1 has shaken the tech and geopolitical world. It has ramifications in many areas. We have analyzed every aspect of its impact.

The Chinese New Year 2025 began on January 29. This new year is the year of the Wood-Snake.
Philosophically, the Snake’s ability to shed its skin represents renewal and the continuous process of reinvention.
A constant change that keeps evolving the being.
Just as the spirit of innovation has driven the launch of DeepSeek, a groundbreaking AI model that aims to challenge established players on the global stage.
In many ways, DeepSeek embodies the dual qualities of the Wood Snake: a blend of calculated wisdom and organic growth.
Seen in the global context, the year of the Wood Snake may be a harbinger of immense change to come.
Innovation breeding enhanced understanding, learning and adaptability for mankind via AI may be something that we all may be hoping for.
Or it could be our end.
Please Contribute to Drishtikone
What we do takes a lot of work. So, if you like our content and value the work that we are doing, please do consider contributing to our expenses. Choose the USD equivalent amount in your own currency you are comfortable with. You can head over to the Contribute page and use Stripe or PayPal to contribute.
I am thrilled to announce that I will be speaking at the Alternate Media Conference 2025 at the Constitution Club, New Delhi, on March 1-2. The theme for this year’s event is "Unstoppable Bharat", and the lineup of speakers is nothing short of extraordinary.

This is your chance to witness thought leaders, engage in transformative conversations, and interact directly with the speakers. Don’t miss this opportunity—grab your passes now: [Alternate Media Conference Passes].
Let’s come together to support independent voices and bold narratives.
Your donations to The Alternate Media can make it possible to host such impactful events. Be a part of this movement—donate generously and fuel the unstoppable rise of Bharat!
Send Donations to: Paytm : 9717753351 / Phonepay :9717753351 / Google Pay :9717753351 / Paypal : @thealternatemedia
DeepSeek is Launched
DeepSeek officially launched its R1 model on January 20, 2025. Prior to this, a preview version named DeepSeek-R1-Lite-Preview was made available on November 20, 2024.
DeepSeek had just pulled off what can only be described as a paradigm shift in AI economics.
Apparently, armed with a few thousand crippled Nvidia Hopper H800 GPU accelerators — hobbled by performance caps (they were performance-capped versions of Nvidia’s full-power GPUs, specifically limited for the Chinese market due to U.S. export restrictions on advanced AI chips) — it has built a Mixture of Experts (MoE) foundation model that now stares down the behemoths of AI: OpenAI, Google, and Anthropic. Look at the metrics below.
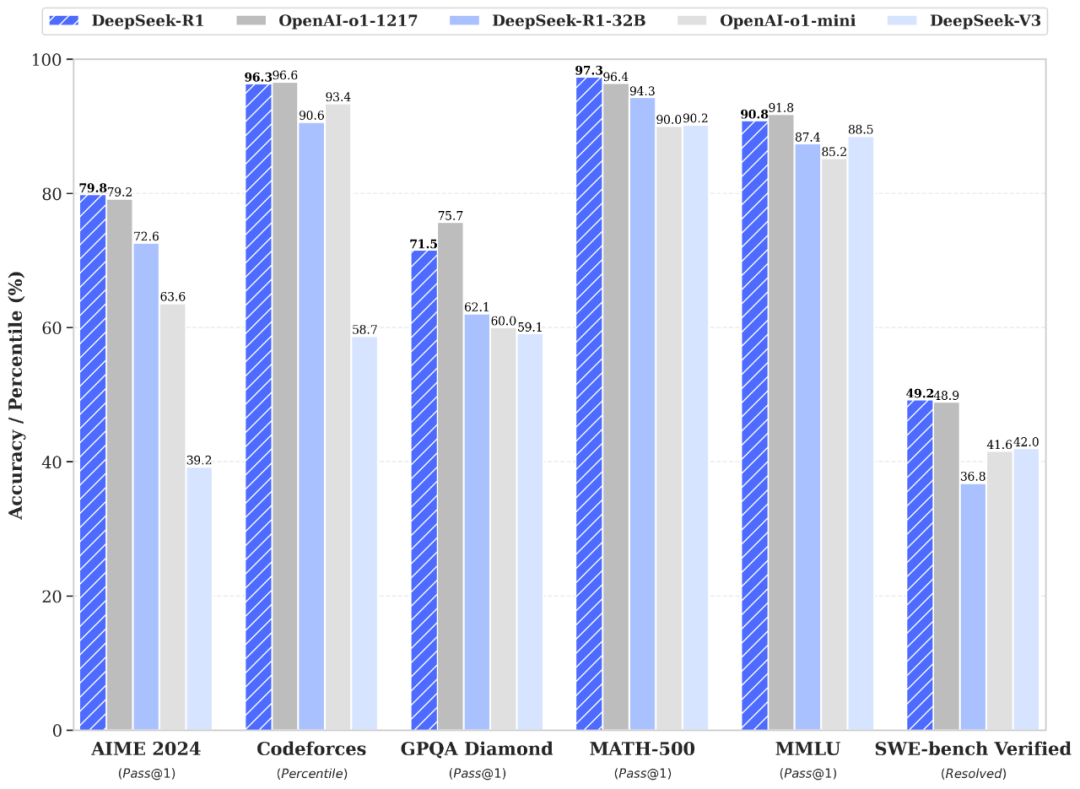
These titans, flush with resources, have hitherto trained their models on tens of thousands of unshackled GPUs, believing brute force was the only path to dominance.
But DeepSeek’s approach flips the script. If a model of this caliber can be trained on just one-tenth or even one-twentieth the hardware, the implications, experts averred - were staggering. The AI market’s valuation could shrink by a factor of 10X to 20X.
This wasn't just a technological breakthrough; it was a financial earthquake!
The market understands what this means. Nvidia’s stock—once the undisputed kingmaker of AI hardware—had plunged 17.2% in real time. The old rules of AI economics are crumbling.
Interestingly, the Chinese AI firms seem to be developing methods to circumvent U.S. export restrictions by optimizing software, training methods, and model architectures — a reality that could reshape the AI arms race.
OpenAI CEO Sam Altman is feeling the heat and has finally acknowledged the Chinese startup DeepSeek's R1 as "an impressive model." He was specifically saying this for its cost-effectiveness. (Source: Bloomberg)
Of course, he had to mention that OpenAI will deliver superior AI models.
Meanwhile, he was also forced to acknowledge that OpenAI may have taken a wrong turn by going to the closed model as opposed to the Open Source model of Deepseek.
Sam Altman, CEO of OpenAI, publicly acknowledged that the company may have taken the wrong path by not supporting open-source AI development. This comes in light of Chinese company DeepSeek's release of their open-source R1 model, which rivals OpenAI's systems at a fraction of the cost, shaking up the market and triggering significant stock movements. Altman's admission highlights the growing industry shift towards transparency and the democratization of AI. (Source: Opentools)
One can very well understand why Altman would have done that.
US Companies Adopting DeepSeek Model
US companies have quickly begun integrating the DeepSeek R1 open source model into their platforms, demonstrating a growing trend toward leveraging advanced, community-driven AI innovations.
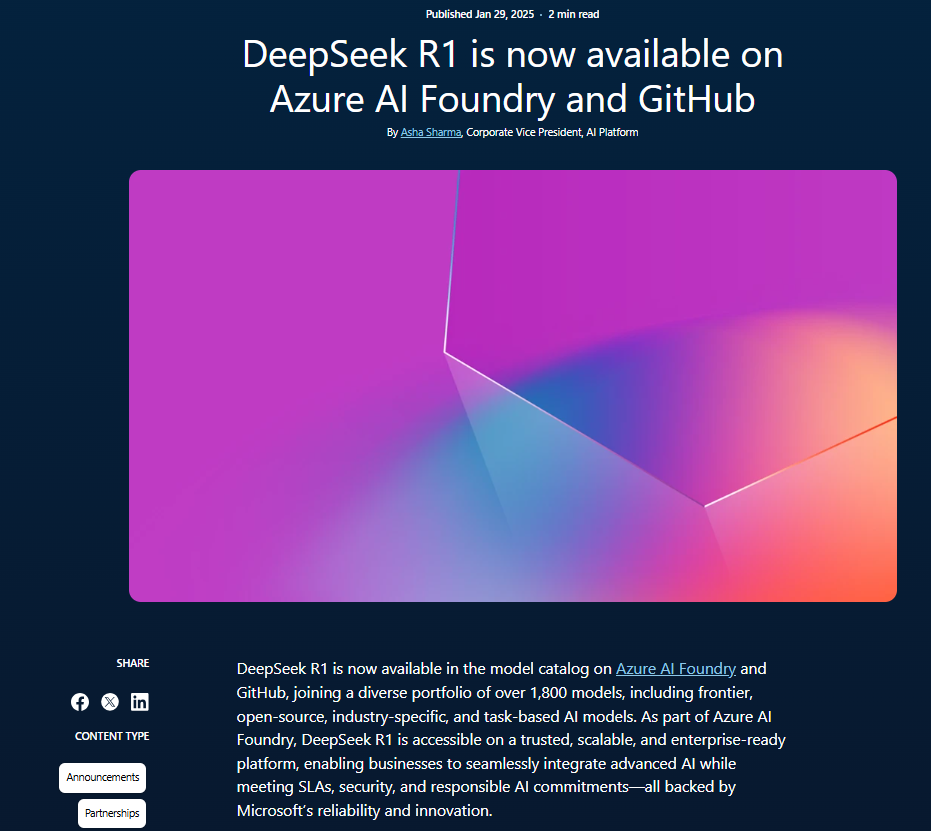
Microsoft has taken a significant step in enhancing its artificial intelligence capabilities by integrating DeepSeek's cutting-edge R1 artificial intelligence model into its Azure AI Foundry platform and GitHub.
For instance, Microsoft has incorporated DeepSeek R1 into its Azure cloud services, using its sophisticated natural language processing and reasoning capabilities to boost enterprise-grade AI applications.
By embedding DeepSeek R1 within Azure, Microsoft is enhancing its cloud platform's ability to deliver more nuanced analytics, better customer service, and advanced decision-making tools to diverse clients.
The Azure AI Foundry platform, known for its robust suite of tools and services, now offers developers and enterprises access to over 1,800 diverse AI models, empowering them to build innovative solutions across industries.
DeepSeek's R1 model, with its powerful performance and affordability, could democratize AI adoption further, enabling businesses of all sizes to leverage advanced AI capabilities without incurring prohibitive costs.
Very powerful move indeed.
Google Cloud and AWS won't be far behind.
Also, Perplexity AI has indeed integrated the DeepSeek R1 model into its Pro Search offering, marking a significant development in AI-powered search capabilities. This integration allows Pro subscribers to leverage the advanced reasoning capabilities of DeepSeek R1 directly within the Perplexity platform.
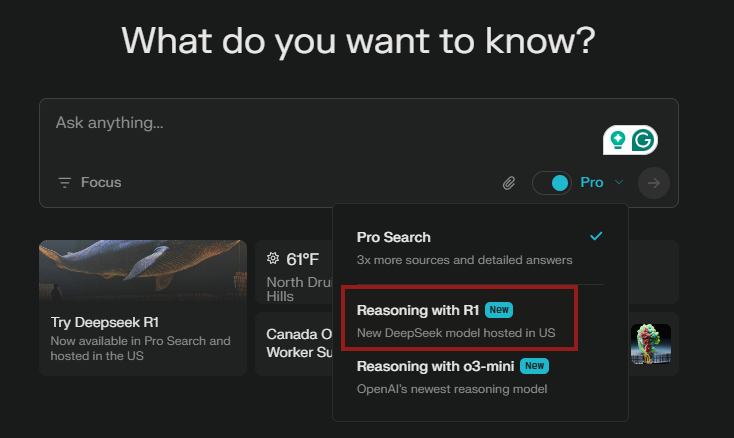
What does this offer the Perplexity users?
- Increased Query Limits: Perplexity has expanded the daily DeepSeek R1 query limit for Pro users from 10 to 25, with some reports suggesting it may have been further increased to 500 queries per day.
- US-Based Hosting: To address privacy and security concerns, Perplexity hosts the DeepSeek R1 model on servers located in the United States and Europe, ensuring that user data does not go to China.
- Uncensored Results: Perplexity has implemented measures to ensure that the DeepSeek R1 model provides uncensored results, even for politically sensitive topics.
- Integration with Other Models: Pro users can choose between multiple AI models, including DeepSeek R1, OpenAI's GPT-4, and Anthropic's Claude 3.5
These companies are doing all this because R1 is an open-source model. What does that mean?
The AI System Components: A Primer
Three steps are critical for building a powerful AI system - Selecting an AI Model (OpenAI or Deepseek R1), Gathering the data to train, and Training the model on that data.
Selecting the AI Model: The AI model is like the brain of your system. Choosing the right one is like picking the best engine for a car. You can either create your own AI model (which is complex and expensive) or use an existing one like DeepSeek R1. Using an open-source model is like borrowing a really good recipe instead of inventing one from scratch. The main questions to ask in this case are:
- Does the model fit your needs? (e.g., text, images, or something else?)
- Is it open source (like DeepSeek R1) or paid (like some OpenAI models)?
- Can it handle the size and complexity of your project?
Gathering the Data to Train the AI Model: Data is the fuel for your AI. Without good data, your AI won’t learn properly. Think of it like teaching a kid— if you only show them half the array of the alphabet, they’ll never learn to read. AI learns from data, just like you learn from reading books. You need a lot of high-quality data to train your AI. For example, if you’re building an AI to recognize cats, you’ll need thousands of pictures of cats. Some of the questions that one needs to ask are:
- Is the data high-quality? (No mistakes or junk information.)
- Is there enough data? (More data usually means a smarter AI.)
- Is the data relevant? (If you’re building an AI to recognize dogs, you don’t want cat pictures in your dataset.)
Training the Selected Model on the Data Gathered: Training is where the magic happens. This is when your AI learns from the data and gets smarter. This is where you teach the AI. You feed it the data and let it learn patterns. For example, if you’re teaching it to recognize cats, it will learn what makes a cat look like a cat (pointy ears, whiskers, etc.). What are the critical questions to consider here? These:
- Do you have enough computing power? (Training big AI models requires powerful computers.)
- How long will it take? (Training can take hours, days, or even weeks.)
- Are you testing as you go? (You need to check if the AI is learning correctly or making mistakes.)
Just see why these three steps are the critical part of an AI system.
- Selecting the model gives you the foundation.
- Gathering data gives you the knowledge.
- Training the model turns that knowledge into intelligence
If you get these three steps right, you’re well on your way to creating something amazing!
However, at the end of the day, an AI system - Model and the Data - is a system with a loop, just like our mind and brain function. It needs to be improved over time and fine-tuned. So, these functions also need to be performed:
- Preprocess the Data: Clean and organize the data before training. (Think of it like washing vegetables before cooking.)
- Test the Model: After training, you test the AI to see how well it works. If it makes mistakes, you tweak it and train it again. This is like practicing a sport—you keep getting better over time. (Like taking a practice test before the real one.)
- Deploy the Model: Once the AI is good enough, you put it to work. This could mean putting it in an app, a website, or even a robot. For example, you could create an app that helps people identify plants using your AI. (This is like launching your rocket after building it.)
- Monitor and Improve: Keep an eye on the AI and make updates as needed. AI is never really “finished.” You keep improving it by adding more data, fixing bugs, and adding new features. It’s like leveling up in a video game—you keep getting stronger and smarter. (Like giving your car regular tune-ups.)
One of the most significant impacts with respect to US stocks has been on Nvidia. Why is that? Because chips are central to creating the correct infrastructure. The hardware and computing power required to train an AI model would typically include:
- GPUs (Graphics Processing Units): Nvidia GPUs are the most popular for training AI models because they can handle thousands of calculations at once. GPUs are like the "muscle" of AI training.
- TPUs (Tensor Processing Units): These are specialized chips designed by Google specifically for AI training. They’re faster than GPUs for specific tasks but less flexible.
- Cloud Computing: Instead of buying expensive hardware, many companies use cloud platforms like AWS, Google Cloud, or Microsoft Azure. These platforms let you rent powerful computers by the hour.
- Storage: You need a lot of space to store your data and the trained model. This could be on physical servers or in the cloud.
- Networking: Fast internet connections are important for transferring large amounts of data, especially if you’re using cloud services.
In terms of the software and frameworks that help to build and train an AI model, these are the important components:
- Machine Learning Frameworks: Tools like TensorFlow, PyTorch, or Hugging Face are like the "construction kits" for AI models. They provide the building blocks for creating and training models.
- Programming Languages: Python is the most popular language for AI development because it’s easy to use and has tons of libraries for AI.
- Data Processing Tools: Tools like Pandas, NumPy, and Apache Spark help you clean, organize, and prepare your data for training.
- Version Control: Tools like GitHub help you keep track of changes to your code and collaborate with others.
Finally, we come to the costs and the resources needed. We discussed this a lot in our previous newsletter.

The list would include:
- Hardware Costs: Buying GPUs or TPUs can cost thousands to millions of dollars. For example, a single high-end Nvidia GPU can cost over $10,000.
- Cloud Costs: Renting cloud computing power can range from a few dollars per hour to tens of thousands of dollars for large-scale training.
- Electricity: Training a big model can use a lot of power, which adds to the cost.
- Data Costs: Collecting, cleaning, and storing data can also be expensive, especially if you need to buy datasets or hire people to label data.
- Personnel Costs: You’ll need skilled engineers and data scientists to build and train the model, and their salaries can be high.
With the basics of the AI systems out of the way, we can now start discussing the details.
Power of AI - Collapsing the Evolution?
What is the power of these AI models and their ability to crunch data and process that to create intelligence and go to the next level of information can be gathered from this one work.
Researchers at EvolutionaryScale and the Arc Institute have developed ESM3, an advanced AI model capable of simulating protein evolution on an unprecedented scale, creating esmGFP—a novel green fluorescent protein with unique properties and transformative potential.
They have collapsed 500 million years of evolution to just a few minutes using an AI language model. Traditional notions of creativity and discovery have always placed nature and slow, stepwise evolution as the primary forces of biological innovation. Now, AI is accelerating biological innovation in a way that seems almost godlike—creating in minutes what nature took eons to develop.
More than three billion years of evolution have produced an image of biology encoded into the space of natural proteins. Here we show that language models trained at scale on evolutionary data can generate functional proteins that are far away from known proteins. We present ESM3, a frontier multimodal generative language model that reasons over the sequence, structure, and function of proteins. ESM3 can follow complex prompts combining its modalities and is highly responsive to alignment to improve its fidelity. We have prompted ESM3 to generate fluorescent proteins. Among the generations that we synthesized, we found a bright fluorescent protein at a far distance (58% sequence identity) from known fluorescent proteins, which we estimate is equivalent to simulating five hundred million years of evolution. (Source: "Simulating 500 million years of evolution with a language model" / Science.org)
Are we still "discovering" evolution, or are we now engineers of life itself? The ability to accelerate evolution could lead to unintended consequences—creating organisms or proteins with unknown long-term effects.
These are essential and critical implications that can only ignored to our - humankind's - own peril.
In this scenario comes DeepSeek R1 from China—a powerful and cheap AI model.
How DeepSeek Did It?
Deepseek was able to achieve its feat of such a powerful LLM DeepSeek's due to the rapid progress by its V3 model, which reportedly utilized 2,048 Nvidia H800 chips for training.
According to DeepSeek, V3 was trained using just 2,048 NVIDIA H800 GPUs – though it’s worth noting there’s some skepticism floating around about just how accurate this figure is. Why does it even matter? Because AI giants like OpenAI, Meta and Anthropic use manymore GPUs to train their models. For instance, OpenAI’s GPT-4 was trained using an estimated 25,000 Nvidia GPUs while Meta used two 24,000-GPU clusters to train its Llama 3 model. (Source: "Does DeepSeek change the game for data center builders?" / Fierce Network)
Of course, H800s are far inferior to the H200s and H100s because their architecture and tech is far more advanced.

Interesting!
An X handle called Aravind shared an interesting thought.
This is what I would say Deep Seek is:
— Aravind (@aravind) January 26, 2025
Llama3 distilled, fine tuned, and to do "thinking"
Done by an advanced lab run by PLA
With illegally obtained highest end AI chips
Soon I'm sure all three will turn out to be true. I don't know how AI works, but I know how China works. https://t.co/s6JNiLNYyM
How they trained the model in its nitty-gritty may be something that we can question. But what we cannot question is power of its code.
So, one thing seems beyond doubt: the paper detailing the model does show optimizations that could have made such a thing possible.

Let us take a sneak peek into what went into training the model in an efficient way.
The Multi-stage Training Model
For our sake, here is a quick primer on terms and concepts that will help us understand.

Now let us understand how DeepSeek approached learning using the Reinforcement Learning mechanism and how it progressively worked through the kinks.
Imagine teaching a language model by rewarding it for giving good answers. Traditionally, this is done using a method that includes a “coach” model—a helper that scores the computer’s responses based on pre-tagged examples. This method works well when the examples are accurate and complete. However, the coach’s feedback can fall short if the examples are limited or biased.
A newer approach called Group Relative Policy Optimization (GRPO) was evolved that removes this coach entirely.
Instead, GRPO relies on simple rules—such as whether an answer is coherent, complete, and fluent—to judge each response. The model then compares its performance against the average of a group, learning over time what a “good” answer should look like. Using GRPO, the DeepSeek-R1-Zero model showed impressive results on reasoning tasks and even performed well in a popular math competition (AIME 2024).
Now, while this method boosted the model’s reasoning ability, it also led to issues.
Without the structured guidance of labeled data, the R1-Zero model sometimes produced outputs that were hard to read and mixed languages unexpectedly.
To overcome these challenges, the developers introduced a multi-stage training process with the DeepSeek-R1 model. In the first stage, the model was trained using GRPO to build strong reasoning skills.
Then, in subsequent stages, the model underwent supervised fine-tuning with carefully curated data. This additional training focused on enhancing language quality, ensuring that the model’s output was clear, well-formatted, and stylistically consistent.
Extra filtering measures and targeted datasets helped reduce the unwanted language mixing.
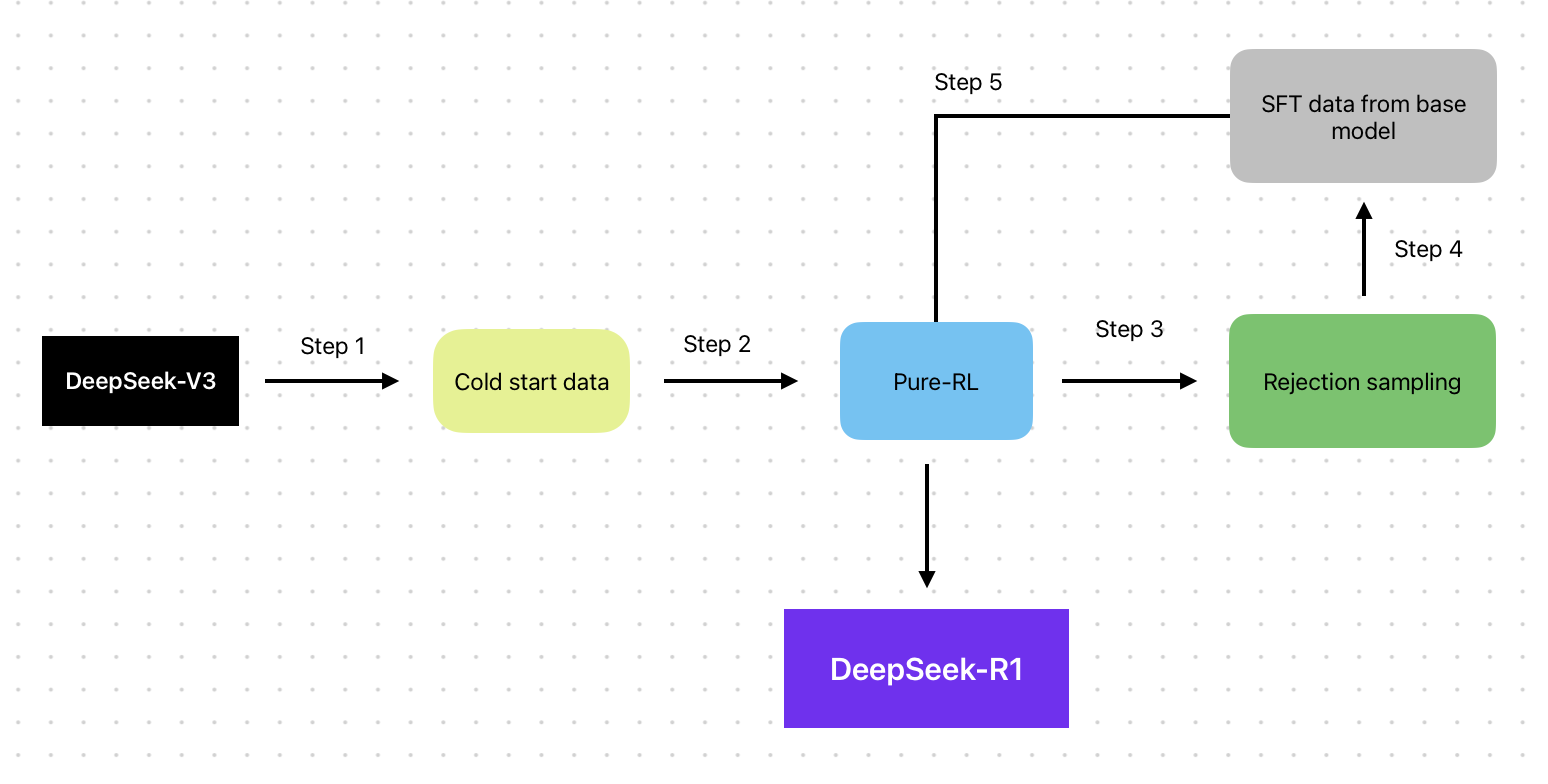
By blending the strengths of GRPO with the precision of supervised fine-tuning, the DeepSeek-R1 model not only maintained its excellent reasoning performance but also achieved more polished, coherent, and readable outputs.
This multi-stage approach shows that combining different training strategies can effectively address the limitations of using a single method.
(Source for the information: Breaking down the DeepSeek-R1 training process—no PhD required / Vellum)
This is what gave DeepSeek R1 its power.
In order to better understand the Deepseek R1 model further, you can also watch this video by a retired Microsoft engineer, which does a good job of breaking things down in an easily comprehensible way.
Everything sounds great. Almost too good to be true.
Did DeepSeek Plagiarize?
Yes the model that DeepSeek R1 offers is indeed great. It is also possible (though not confirmed) that it may have indeed used the Nvidia H800 hardware to train.
But did they cut no corners to come to market so quickly?
Well, there is evidence suggesting that DeepSeek may have used data from ChatGPT to train its R1 model.
OpenAI, the creator of ChatGPT, claims to have found evidence that DeepSeek used a technique called "distillation" to extract knowledge from ChatGPT models.

What's distillation? Distillation involves using outputs from a larger AI model to train a smaller one, effectively transferring knowledge between models.
In fact, the US Commerce Secretary has called DeepSeek a "technology thief".

One interesting video by an Instagrammer showed how she found curious proof within DeepSeek itself! Check it out.
How did China - and Deepseek get its Chips?
So the most fundamental question that has come up with respect to the achievements touted by Deepseek is - Was all this really done with 2048 H800 chips - no H100s?
Experts are skeptical about this claim.
One unanswered question is how DeepSeek achieved such an impressive performance from its AI model without using Nvidia’s top-of-the-line H100 chips. The U.S.-made chips are export-restricted. Alexandr Wang, the CEO of Scale AI, has a theory: “My understanding is that DeepSeek has about 50,000 H100s which they can’t talk about, obviously, because it is against the export controls that the United States has put in place.” (Source: "‘Is DeepSeek a DeepFake or real?’ Doubts and questions emerge on Wall Street and in Silicon Valley" / Fortune)
The one easiest way that Deepseek (and other Chinese companies possibly) could have gotten these chips is via smuggling routes. Smuggling in chips, it so seems, is quite rampant.
Both Nvidia and the U.S. government have argued that the scale of smuggling was limited. But The Times last year reported an active trade in China in restricted A.I. technology. In a bustling market in Shenzhen, in southern China, chip vendors reported engaging in sales involving hundreds or thousands of restricted chips. Representatives of 11 companies said they sold or transported banned Nvidia chips — including A100s and H100s, the company’s most advanced at the time — and The Times found dozens more businesses offering them online. One vendor in Shenzhen showed a reporter messages arranging deliveries of servers containing more than 2,000 of Nvidia’s most advanced chips, a transaction totaling $103 million. Since then, more reports have emerged documenting large-scale smuggling, particularly through other countries in Asia. (Source: Do China’s A.I. Advances Mean U.S. Technology Controls Have Failed? / New York Times)
So, it shouldn't come as a surprise that U.S. officials in the White House and the FBI are probing allegations that DeepSeek may have sidestepped export controls by channeling banned Nvidia chips through intermediaries in a Southeast Asian nation. Sources indicate that DeepSeek’s latest V3 model was trained using Nvidia’s H800 chips—specially engineered for the Chinese market but banned by the U.S. in October 2023.
In response to this prohibition, Nvidia has now released its H20 chips, tailored to navigate the new regulatory landscape. In continuation of the stringent tech restrictions initiated under the first Trump administration and further enhanced by the Biden administration, the Trump 2.0 administration is weighing additional measures that could extend to the H20 series.

This competition and chip trade war will only grow.
Recent U.S. actions have expanded semiconductor technology restrictions, broadening both the list of affected components and the geographic parameters of these trade rules.
Howard Lutnick, President Donald Trump’s contender to lead the Commerce Department, hinted at the possibility of DeepSeek bypassing the U.S. embargo. Singapore accounts for about 20% of Nvidia’s revenue, Bloomberg cites regulatory filings. Reportedly, Nvidia shipments to Singapore were insignificant. The country had remained unscathed by the semiconductor embargoes so far. (Source: How Did DeepSeek Get Access To Nvidia Chips? US Investigates Possible Embargo Violation / Benzinga)
As regulators tighten the noose on critical technology transfers, do you see how innovation, international commerce, and national security are deeply intertwined in today’s globalized tech arena?
Is DeepSeek a Trojan Horse?
Then, there is the risk of espionage and data theft that needs to be evaluated. There are major concerns regarding the privacy and security of data processed by DeepSeek, given that its servers are based in China, where data laws might allow government access.
Of course, there are concerns regarding the data being used for intelligence gathering or to influence global narratives. The comparison to TikTok, another Chinese app that has faced scrutiny over data privacy, has been noted in discussions about DeepSeek.
DeepSeek brings your user data via ByteDance under the control of the Chinese govt. It can be used as a spy tool. pic.twitter.com/UuUXjE6faF
— ruediger drischel (@RudyDrischel) January 28, 2025
Many see DeepSeek as a strategic asset in China's broader plan to counter U.S. tech supremacy. Its success might force the U.S. to either accelerate innovation or impose even stricter export controls, further fueling tech tensions.
The notion of DeepSeek being a "Trojan Horse" arises from concerns that its widespread use - because of it being an Open Source model (counterintuitively!) could give China key strategic benefits — such as the ability to shape global AI standards or to amass extensive user data from around the world.
DeepSeek as a "Trojan Horse" in geopolitical terms involves a nuanced understanding of technology's role in international politics.
While there are valid concerns about data security, privacy, and strategic intentions, the open-source model of DeepSeek also promotes a narrative of global tech democratization. Whether it serves as a geopolitical tool for China or a genuine contributor to the global tech ecosystem depends heavily on how its technology is adapted, regulated, and integrated into various national frameworks.
Meanwhile, this "Sputnik Moment" has pushed the American companies to do more.
Pushing American Competitors
The impact of Deepseek on OpenAI has been such that the American company has launched an "Operator" (Jan 23rd, 2025).

Here is a quick preview of that agent and what you can do with it.
Meanwhile, Perplexity has also launched a similar agent for Android. The Perplexity Assistant seamlessly integrates with Android applications, enabling it to manage intricate tasks and execute follow-up actions efficiently.

Arvind Srinivas shared a thread on the Perplexity Assistant on X. Worth reading.
We are excited to launch the Perplexity Assistant to all Android users. This marks the transition for Perplexity from an answer engine to a natively integrated assistant that can call other apps and perform basic tasks for you. Update or install Perplexity app on Play Store. pic.twitter.com/FSRDLtVWzB
— Aravind Srinivas (@AravSrinivas) January 23, 2025
Imagine having an Alexa on steroids. If you want to travel to Aruba, you tell Alexa, and it will make bookings with your favorite options and the cheapest way available. With tickets in your inbox and 24 hours before the flight, the boarding passes will be sent to your phone text.
The DeepSeek Crash: Who Made the Money?
On January 27th, 2025, Nvidia lost $593 billion in one day because of DeepSeek. The launch raised concerns, and the predicted impact resulted in traders dumping the Nvidia and tech shares.
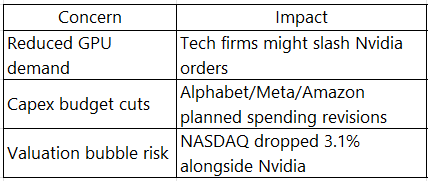
The stock market crash triggered by Chinese AI startup DeepSeek's disruptive low-cost models created significant profit opportunities for short sellers and systematic hedge funds while raising questions about potential insider advantages.
The short sellers made a killing - $6.6 billion on Nvidia in just one day!
Betting against Nvidia has been an awful trade for short sellers. But it was terrific on Monday. The stock’s 17% plunge led to a one-day profit of $6.56 billion for Nvidia shorts, according to research from S3 Partners. Nvidia shorts are now up nearly 11% for the year on this trade. Investors who bought leveraged single stock exchange-traded funds in Nvidia—which amplify their short or long positions in a company through the use of financial derivatives and debt—made an even bigger profit Monday. (Source: MSN)
In fact, if you take the larger impact on the tech sector, the short sellers may have raked in $9 billion from just Nvidia, Broadcom, and Supermicro because of the DeepSeek effect! (Source: HPBL)
The carnage has continued. Because of what some called the Sputnik Moment!

Remember that Chinese Hedge Fund High Flyer (founded in 2015 and based out of Hangzhou, Zhejiang) had the same founder - Liang Wenfeng - as the founder and backer of AI firm DeepSeek. The unexpected ascent of Chinese AI firm DeepSeek has swiftly vaulted its founder, Liang Wenfeng, into the billionaire elite.

The X handle said something very interesting - DeepSeek did a "Hindenberg" on the US market with AI. And further, this stock market crash would have generated enough money for the Chinese to bailout their failing real estate giants like Vanke and Evergrande.
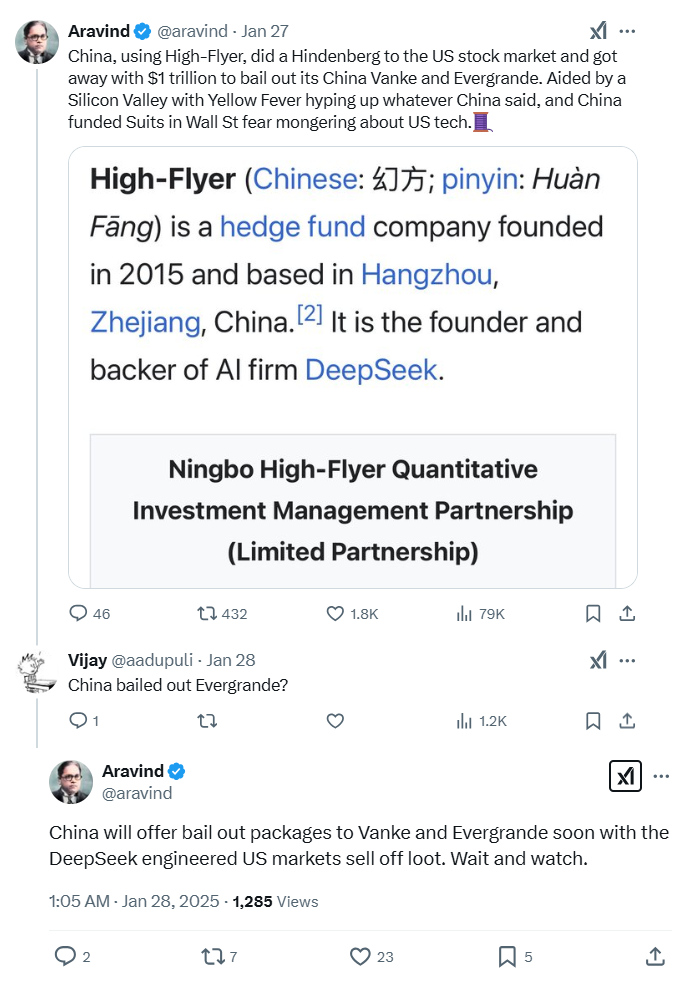
Conspiracy theory?
Well, on January 28th, 2025, the news came of the Vanke bailout! Is that a coincidence?

However, it is not just the short sellers and the Chinese proxies of the CCP establishment who may have made money due to the DeepSeek US market collapse. It is now being alleged that even US politicians like Nancy Pelosi may have "predicted" the events due to the DeepSeek launch.
Interestingly, Nancy Pelosi's pre-crash stock transactions and congressional trades are documented in available records related to the DeepSeek-triggered market collapse, showing a shocking pattern.
Nvidia Stock Sales
- December 31, 2024: Sold 10,000 shares ($1M-$5M value)
- January 14, 2025: Purchased 50 call options ($250K-$500K)
Other Notable Moves
- Apple: Dumped 31,600 shares ($5M-$25M) on Dec. 31
- Tech Sector Pivots: Acquired call options in Alphabet, Amazon, and Vistra while divesting from Nvidia/Apple

Nancy Pelosi's alleged insider trading tactics have been in discussion for a long time. As recently as Trump's inauguration her trades were said to be suspicious.

So now look at this closely.
- The short sellers made money
- The Chinese hedge funds may have made money
- US politicians - allegedly linked to the "Deep State" - made money
How?
Who is working with whom? Who knew? How much?
Most importantly, the critical questions are:
- is China a collaborator of and is working along with the Deep State?
- has China infiltrated and is now controlling the Deep State
- is China now a proxy for the Deep State?
The all-important question is, who is on which side?
The all important question here for many of us will be where is India?
India's AI Mission
Meanwhile, India is making a bold move towards AI self-reliance by launching an ambitious AI mission. The government has announced plans to develop its own foundational AI model, comparable to global leaders like ChatGPT, Gemini, and DeepSeek.
In the next 10 months!
Did someone say its a "Sputnik Moment?" Well it is so for the world!
This initiative is part of a broader strategy to foster innovation, boost the local technology ecosystem, and reduce dependency on foreign AI technologies.
The project aims to create a robust, homegrown AI system capable of understanding and generating human-like text, addressing local language nuances, and catering to unique socio-economic challenges.

India’s AI mission could be as transformative and innovative as UPI and the India Stack. UPI revolutionized digital payments by creating a seamless, interoperable ecosystem, while the India Stack provided a comprehensive digital infrastructure that democratized access to various services. Similarly, the government’s push to develop a foundational AI model is seen as a leap towards self-reliance in an emerging field that is rapidly reshaping global industries.
India’s AI initiative is built on a foundation of strong government support, a vibrant tech startup ecosystem, and a wealth of technical talent.
The focus on creating an AI model tailored to local languages and socio-economic challenges positions the project to address unique needs that global models might overlook. Furthermore, India aims to create an inclusive and trustworthy AI environment by emphasizing ethical AI and data security.
Most importantly for all Indian related topics, the data used to train the models needs to be genuine and not based on past leftist, often anti-India and definitely anti-Hindu works and data.
Comments ()